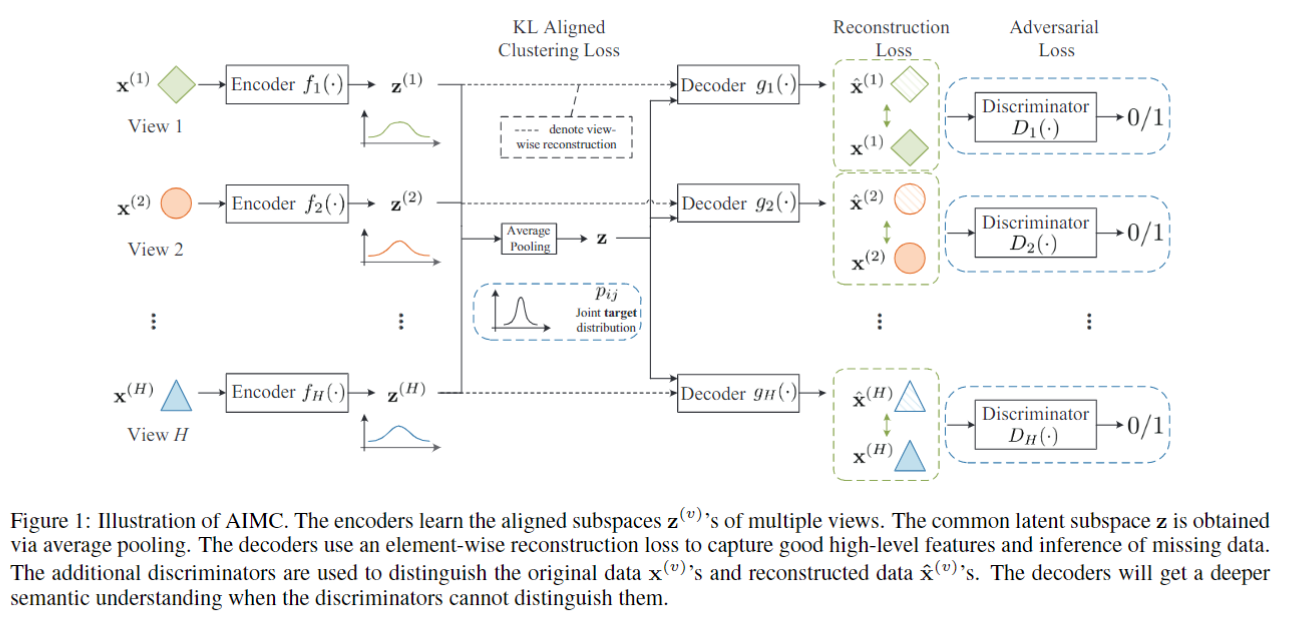
思路:
- 每个视图分别用编码器$f_v(\cdot)$学习相同维度high-level的特征表示 $\mathbf{z}^{(v)}$
- 对所有$\mathbf{z}^{(v)}$做平均池化,得到公共的表示$\mathbf{z}$
- 每个视图分别共用一个编码器$g_v(\cdot)$让$\mathbf{z}^{(v)}$和$\mathbf{z}$重建$\mathbf{x}^{(v)}$
- 每个视图分别用判别器区分原始数据$\mathbf{x}^{(v)}$和生成的$\mathbf{\hat{x}}^{(v)}$
- 对于缺失的样本,可以通过公共表示$\mathbf{z}$生成$\mathbf{\hat{x}}^{(v)}$
损失函数:
逐元素的重建损失
对抗损失
KL-aligned聚类损失:KL-aligned聚类损失仅加给完整的数据,它试图使所有视图的分布一致且紧凑。KL散度计算的是P分布与Q分布之间的差异,其中P表示通过$\mathbf{z}$计算的聚类分布,Q表示通过$\mathbf{z}^{(v)}$计算的t-学生分布(目标分布)
模型训练:
- 对不完整的数据使用该框架训练,得到的公共表示$\mathbf{z}$可以生成缺失的$\mathbf{x}^{(v)}$,进而得到完整的多视图数据
- 对完整的数据再次使用该框架训练,得到的新的公共表示$\mathbf{z}$可以用来做K-means聚类
Maaten and Hinton, 2008: Visualizing data using t-sne.
Xie et al. , 2016 : Unsupervised deep embedding for clustering analysis